Amazon Elastic MapReduce (EMR) is a web service using which developers can easily and efficiently process enormous amounts of data. It uses a hosted Hadoop framework running on the web-scale infrastructure of Amazon EC2 and Amazon S3.
Amazon EMR removes most of the cumbersome details of Hadoop, while take care for provisioning of Hadoop, running the job flow, terminating the job flow, moving the data between Amazon EC2 and Amazon S3, and optimising Hadoop.
In this tutorial, we will first going to develop WordCount java example using a MapReduce framework Hadoop and thereafter, we execute our program on Amazon Elastic MapReduce.
You must have valid AWS account credentials. You should also have a general familiarity with using the Eclipse IDE before you begin. The reader can also use any other IDE of their choice.
In this section, we will first develop an WordCount application. A WordCount program will determine how many times different words appear in a set of files.
- 1. In
Eclipse (or whatever the IDE you are using), create a simple Java project name "WordCount".
- 2. Create a
java class name Map and override the map method as follow:
public class Map extends Mapper<longwritable,
intwritable="" text,=""> {
private final static IntWritable one =
new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new
StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
- 3.Create a
java class name Reduce and override the reduce method as below:
public class Reduce extends Reducer<text,
intwritable,="" intwritable="" text,=""> {
@Override
protected void reduce(
Text key,
java.lang.Iterable<intwritable> values,
org.apache.hadoop.mapreduce.Reducer<text,
intwritable,="" intwritable="" text,="">.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
- 4. Create a
java class name WordCount and defined the main method as below:
public static void main(String[] args)
throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
- 5. Export the
WordCount program in a jar using eclipse and save it to some location on disk. Make sure that you have provided the Main Class (WordCount.jar) during extracting the jar file as shown below:
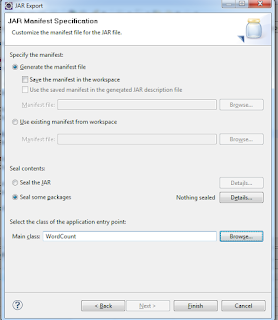

ur jar is ready!!
Step 2 – Upload the WordCount JAR and Input Files to Amazon S3
Now we are going to upload the WordCount jar to Amazon S3.
First, visit the following URL:
https://console.aws.amazon.com/s3/home
Next, click “Create Bucket”, give your bucket a name, and click the “Create” button. Select your new S3 bucket in the left-hand pane. Upload the WordCount JAR and sample input file for counting the words.
Running Hadoop WordCount example
Now that the JAR is uploaded into S3, all we need to do is to create a new Job flow. let's execute the below steps.
(I encourage reader to check out the following link for details regarding each step,
How to Create a Job Flow Using a Custom JAR
)
- 1. Sign in to the AWS Management Console and open the Amazon Elastic MapReduce console at https://console.aws.amazon.com/elasticmapreduce/
- 2. Click Create New Job Flow.
- 3. In the DEFINE JOB FLOW page, enter the following details:
a. Job Flow Name = WordCountJob
b. Select Run your own application
c. Select Custom JAR in the drop-down list
d. Click Continue
- 4. In the SPECIFY PARAMETERS page, enter values in the boxes using the following table as a guide, and then click Continue.
JAR Location = bucketName/jarFileLocation
JAR Arguments =
s3n://bucketName/inputFileLocation
s3n://bucketName/outputpath
Please note that the output path must be unique each time we execute the job. The Hadoop always create a folder with the same name specify here.
After executing a job, just wait and monitor your job that runs through the Hadoop flow. You can also look for errors by using the Debug button. The job should be complete within 10 to 15 minutes (can also depend on the size of the input). After completing a job, You can view results in the S3 Browser panel. You can also download the files from S3 and can analyse the outcome of the job.
Amazon Elastic MapReduce Resources








